ExpressEdit
Video Editing with Natural Language and Sketching



Michal Lewkowicz
Yale University

Alex Suryapranata
KAIST
Michal Lewkowicz
Yale University
Alex Suryapranata
KAIST
ExpressEdit is a system that enables editing videos via NL text and sketching on the video frame. Powered by LLM and vision models, the system interprets (1) temporal, (2) spatial, and (3) operational references in an NL command and spatial references from sketching. The system implements the interpreted edits, which then the user can iterate on.
ExpressEdit’s design is motivated by an analysis of 176 multimodal expressions of editing commands from 10 video editors, which revealed the patterns of use of NL and sketching in describing edit intents.
We present two iterations of ExpressEdit’s interface and the overview of the pipeline.

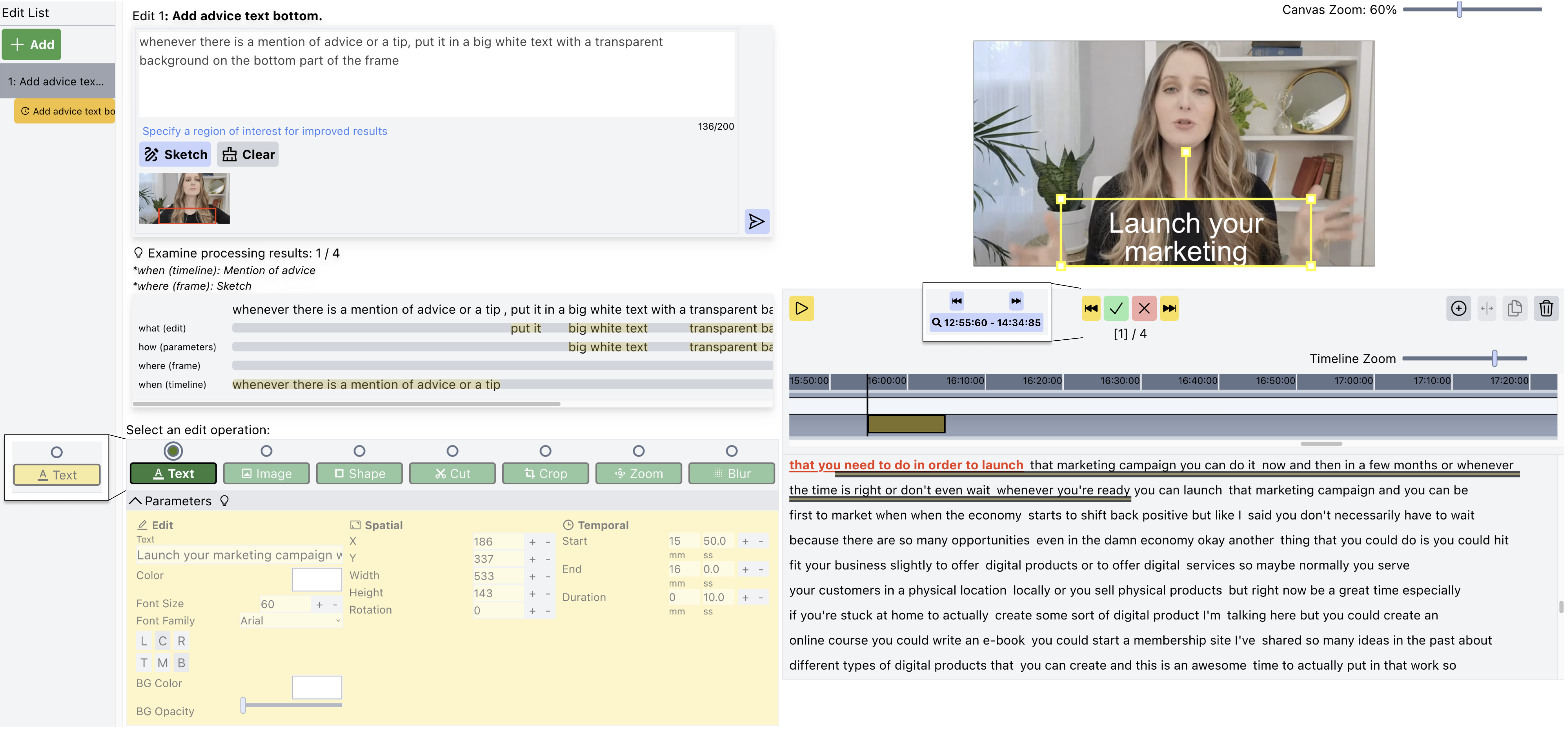
The first iteration of ExpressEdit’s interface is designed to allow users to (1) express their edit commands through natural language text and sketching on the video and (2) iterate on their edit commands as well as manually manipulate the interpretation results.
ExpressEdit supports Edit List that allows the user to add a layer on top of the video that contains a set of edits. The user can press the Add button to add a layer and the edit commands issued by the user will be stored under the same layer.
To describe the edit command, the user can use the Edit Description panel and specify Natural Language Text or Sketch on top of the frame.
ExpressEdit processes the edit command and automatically suggests several candidates at several moments in the video. It automatically specifies the edit parameters & the location of each edit.
ExpressEdit allows users evaluate if the suggestions are appropriate through Examine panel that provides the reasoning for the suggestion. It shows the reasoning for the temporal & spatial location of the edit as well as the breakdown of the NL edit command.
The user can go over the suggestions and either accept them or reject them. The user can manipulate each applied edit manually too.
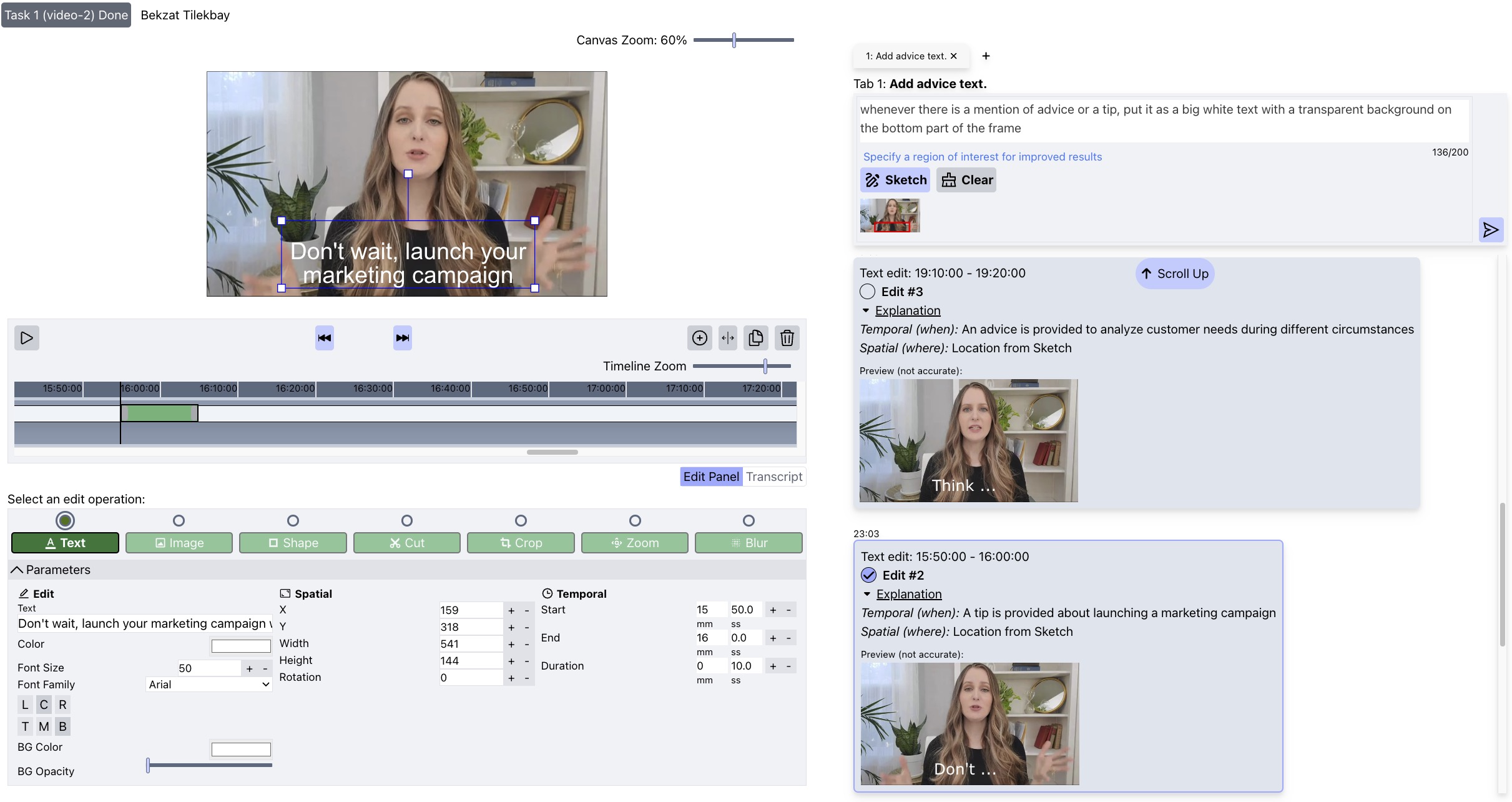
The second iteration of ExpressEdit’s interface is based on findings from the observational study (N=10) conducted with the first version of the interface.
Similar to the first version, ExpressEdit supports Tabs that allow the user to add a layer on top of the video by pressing +. However, now, the user can see the edit commands they issued as well as the suggested edits in the scrollable panel.
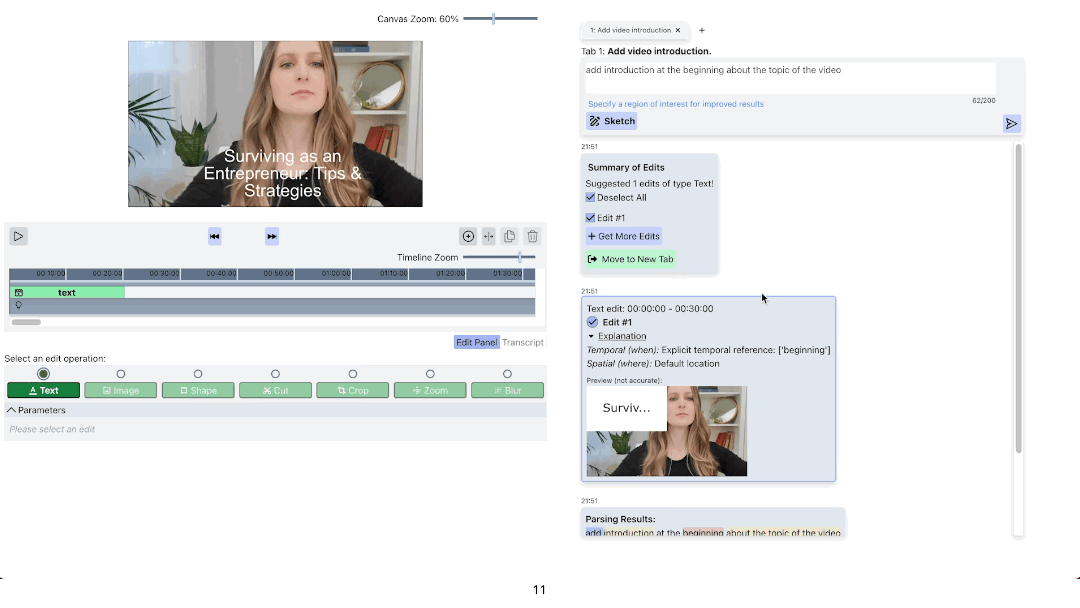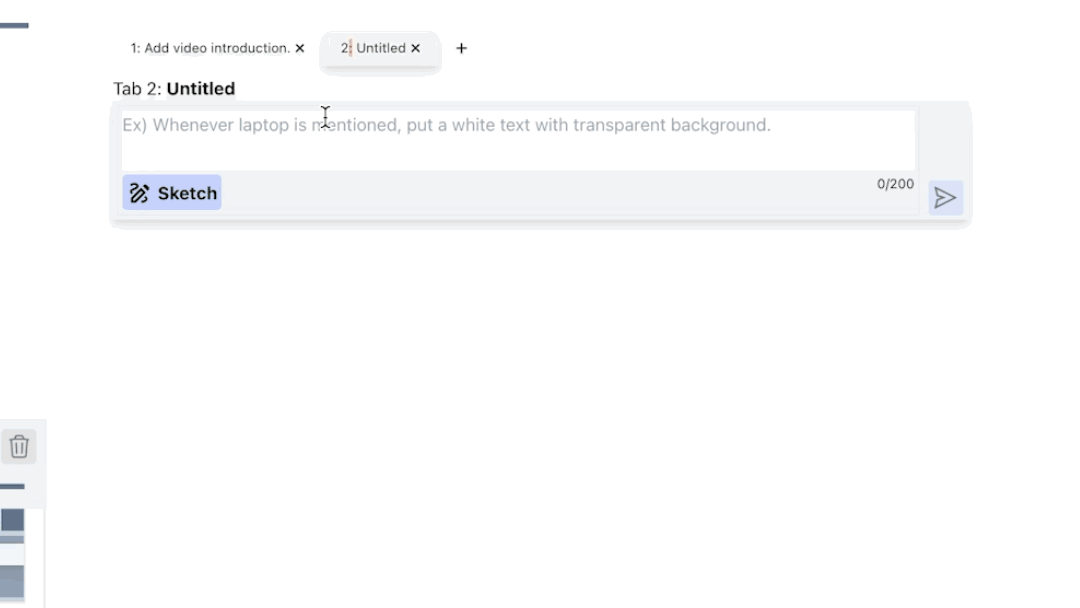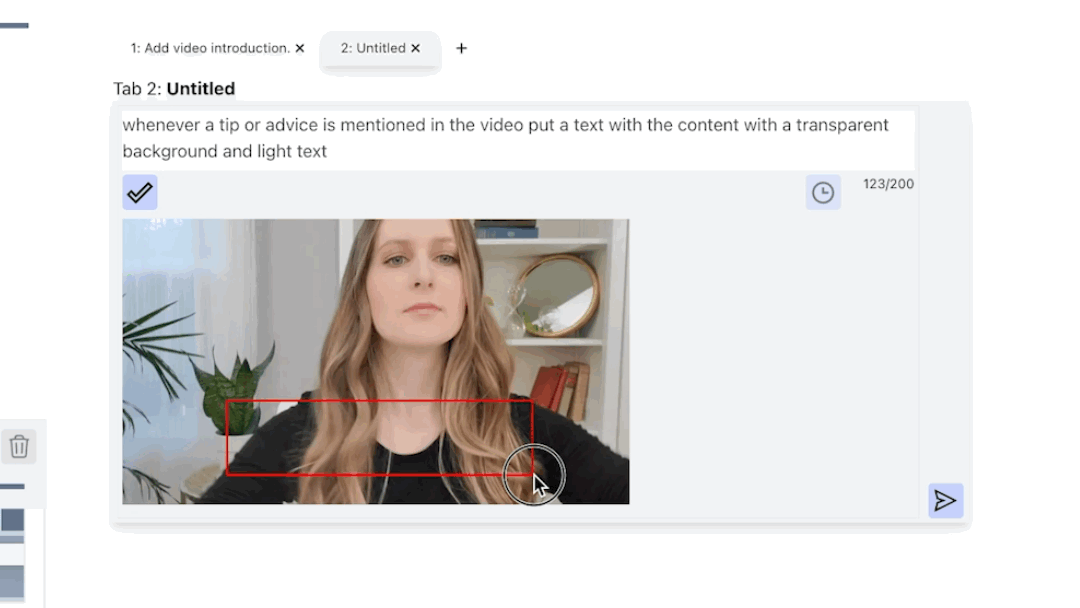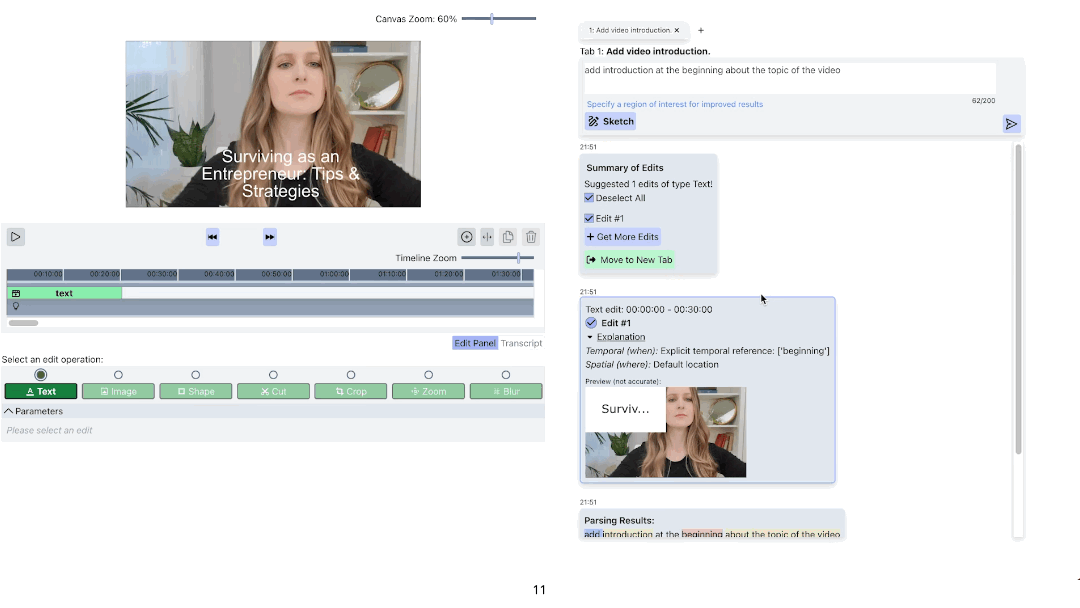
ExpressEdit returns three types of responses after processing the user’s edit command:
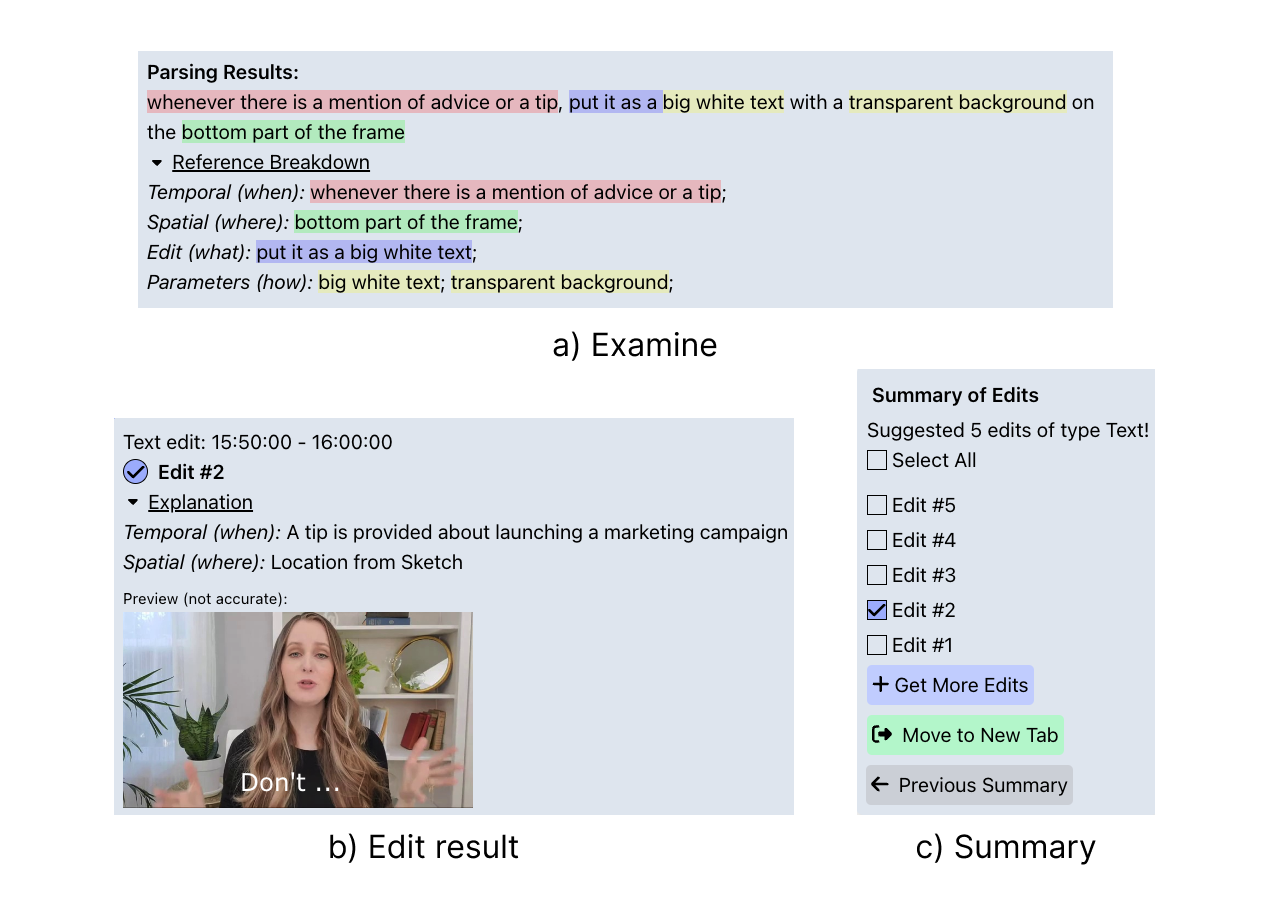
(a) The Examine panel analyzes the user’s natural language command and shows which parts of the input correspond to the description of temporal location, spatial location, and edit operation type and parameters.
(b) The Edit result panel shows the preview of the resulting edit by providing a snapshot of the edit together with explanations on why the segment was selected for the edit to apply.
(c) The Summary panel allows the user to select edits the user wants to apply among generated edits. As well as request more edits, move the set of edits to a new tab, or navigate to the previous summary
Users can browse the suggested edits and turn them on/off as they edit the video.
ExpressEdit is powered by CV & LLM based pipeline that interprets NL & Sketch edit commands. It consists of 2 stages: (1) the offline stage which preprocesses the footage to extract useful metadata; (2) the online stage which interprets the edit commands of the user using the preprocessed metadata.
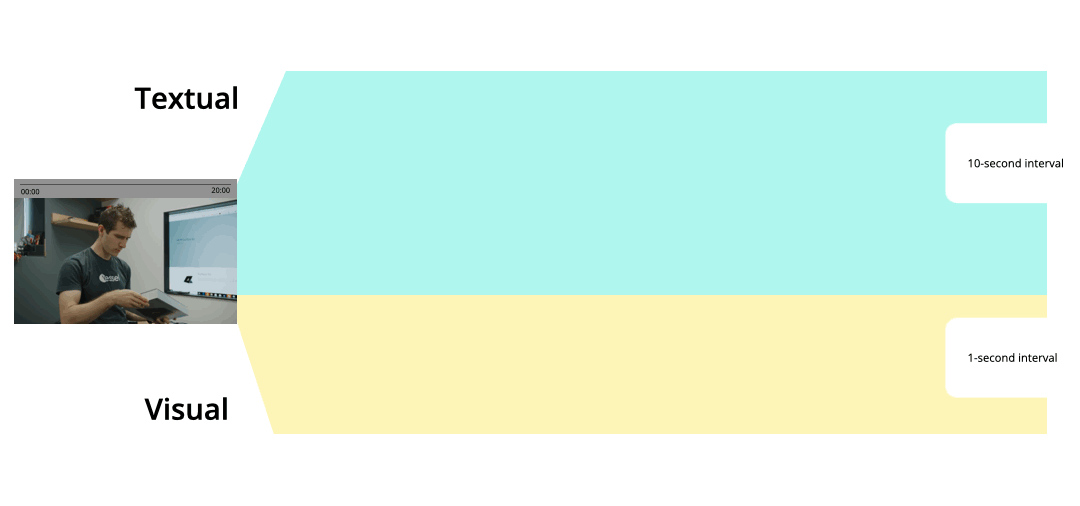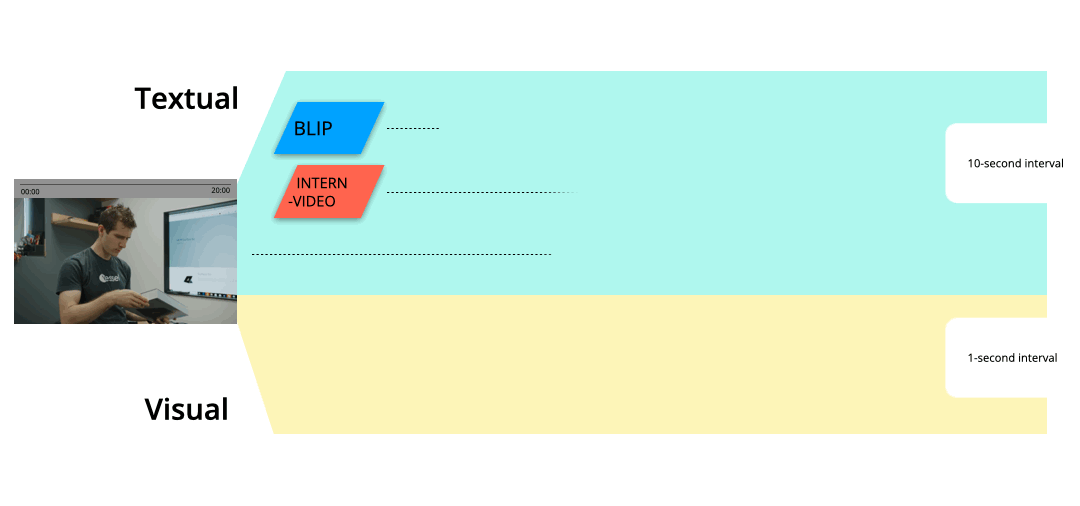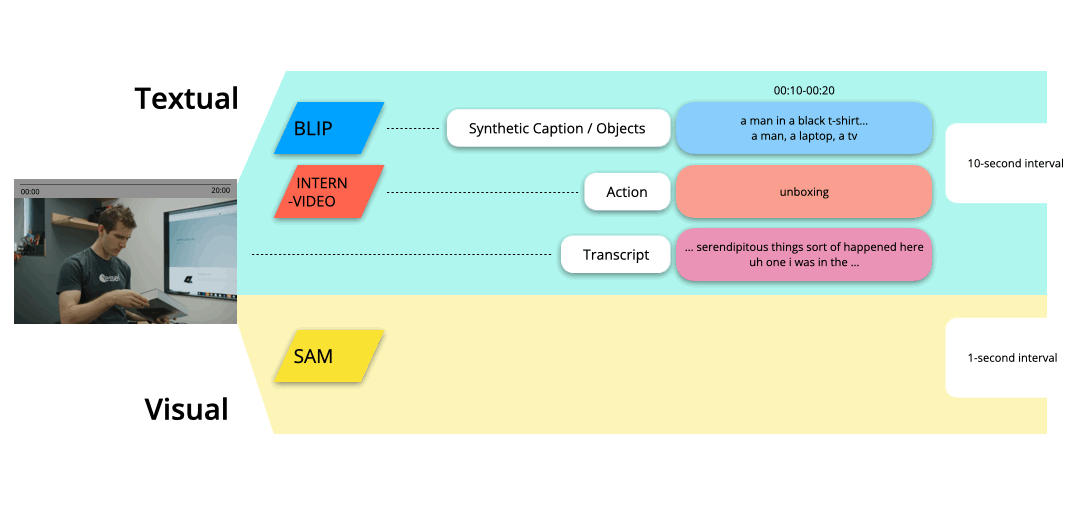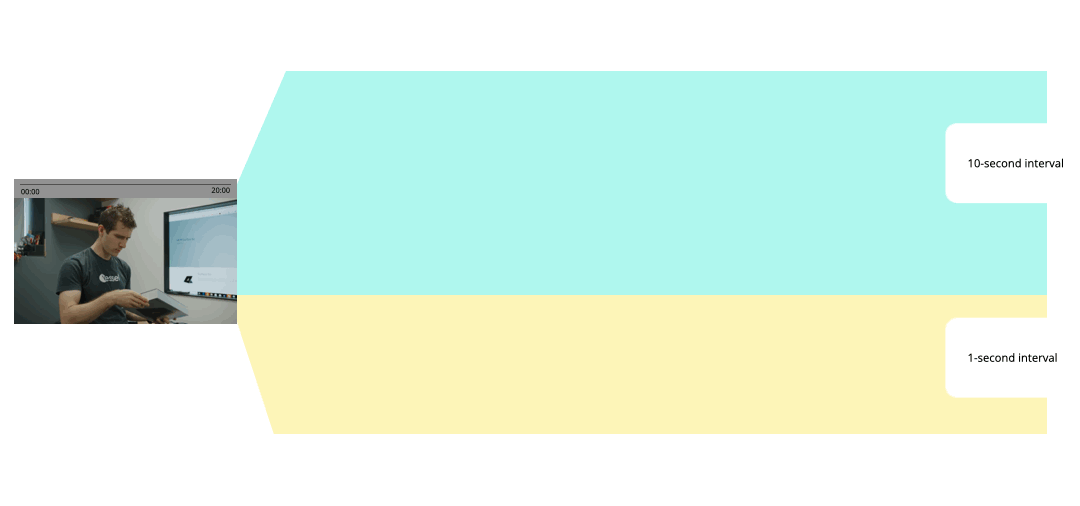
The pipeline first preprocesses the footage video and extracts textual descriptions of 10-second segments and segmentations of each 1-second frame of the video.
Textual descriptions consist of (1) synthetic caption & salient objects by BLIP-2, (2) recognized actions by InternVideo, and (3) transcript from original Youtube video by yt-dlp.
The pipeline also extracts segmentations using Segment-Anything excluding the areas that are small.

As the user issues an edit command, the pipeline parses the NL command and interprets each of the references (temporal, spatial, and edit) by using the preprocessed metadata with corresponding GPT-4 prompts.
In particular, we use both GPT-4 and CLIP to interpret the spatial location as the pipeline may need to consider the user’s sketch and the segmentations from the metadata.
@inproceedings{
tilekbay2024expressedit,
title={ExpressEdit: Video Editing with Natural Language and Sketching},
author={Tilekbay, Bekzat and Yang, Saelyne and Lewkowicz, Michal Adam and Suryapranata, Alex and Kim, Juho},
url={http://dx.doi.org/10.1145/3640543.3645164},
DOI={10.1145/3640543.3645164},
publisher={ACM},
series={IUI ’24},
booktitle={Proceedings of the 29th International Conference on Intelligent User Interfaces},
year={2024}, month=mar,
collection={IUI ’24}
}
![]()
![]()
This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korean government (MSIT) (NRF-2020R1C1C1007587) and the Institute of Information & Communications Technology Planning & Evaluation (IITP) grant funded by the Korean government (MSIT) (No.2021-0-01347, Video Interaction Technologies Using Object-Oriented Video Modeling).
